

Scientific investigations are becoming more and more multidisciplinary, data- and computing- intensive while research data management practices are mainly community-specific. This leads to a fragmentation of the datasets of potential interest for a scientific investigation across a series of diverse data sources with their own discovery and access facilities.
The Federated FAIR Data Space (F2DS) provides tools for both data producers and data consumers contributing to enhance the overall FAIRness of datasets natively dispersed across heterogeneous repositories by realising services for datasets homogeneisation, enrichment and onboarding and services for seamless discovery and access.
With a F2DS, researchers will be able to search, find and retrieve data using a single access point and tool set. Not only does this saves working time because it masks the various access methods of different sources and offers a single access point through user and programming interfaces (UI and API), but it can truly deliver new insights, given the proper combination of selected search criteria and content of one or more data-sets is explored in unison.
The F2DS is a unifying data space that is built by aggregating and enriching datasets from a set of multidisciplinary repositories, i.e. data sources, with the aim to facilitate data discovery and re-use. Although datasets are the primary focus of the resulting data space, other items are managed including repositories and data sources, APIs, metadata schemas and ontologies.
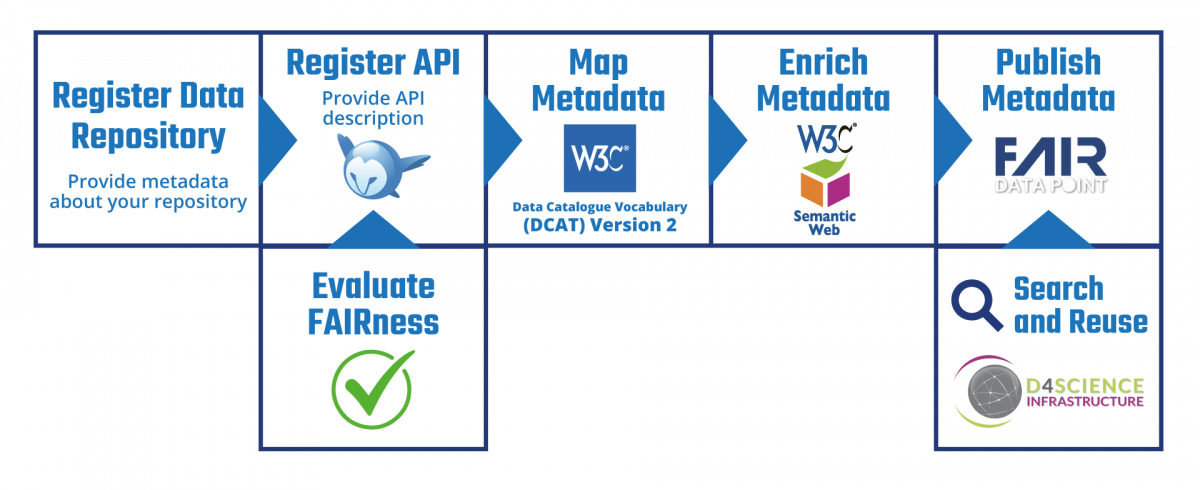
Fig. 1 Pipeline enacted by F2DS Services
It is implemented by two interacting services (see Fig. 2): the Metadata Repository and the Data Catalogue Service.
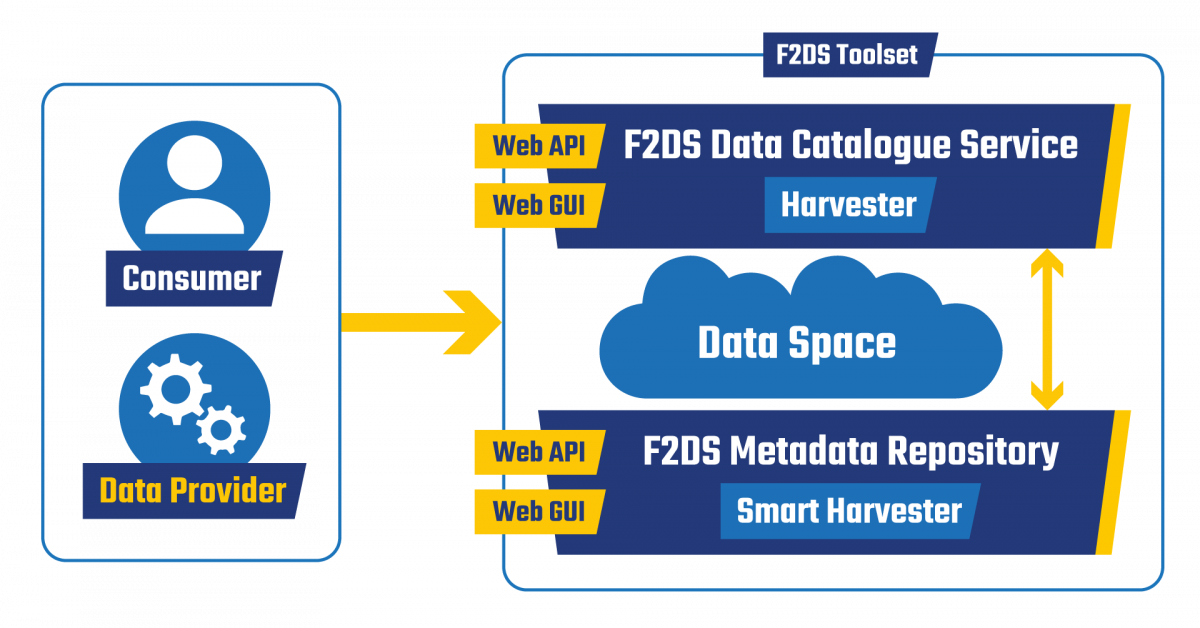
Fig. 2 F2DS Overall Architecture
The Metadata Repository implements a common API description and a simple metadata mapping to automatically and smartly harvest, convert, enrich and publish metadata describing datasets in a single format (DCAT). The Data Catalogue harvests metadata from the Metadata Repository with a dedicated harvester and makes them discoverable and accessible by a data portal based on the CKAN technology.
In the current version of the tool set, the focus has been set on the metadata harvesting and the DCAT mapping in order to publish the metadata to the FDP. The metadata enricher should be added in a later version of the service bundle and should be built leveraging the work of T5.5, e.g. using the FAIRifier service which allows metadata enrichment with ontologies if it is confirmed that it is still the tool of choice.
During the remaining of the project, a study will be carried out to evaluate the feasibility of the integration of F-UJI, an automated tool developed as part of the FAIRsFAIR project which allows a programmatic assessment of the FAIRness of research datasets, and the connection of the FDP graph database with the FAIR Digital Object Framework (FDO-F) . Based on the outcome of this analysis, the decision could be made to implement these new features.
Test the Data Catalogue component